Private AI that runs on your device.
Use Llamatik as a local AI app today — or build your own AI tools with the platform behind it.
No accounts. No tracking. No unnecessary cloud dependency.
One idea: AI should work for you, not the cloud.
Most AI today depends entirely on remote servers. That means your data leaves your device, latency increases, and costs scale with usage.
Llamatik takes a different approach.
By running AI locally, Llamatik gives you more control over your data, faster interactions, and a more sustainable way to use AI — without constant reliance on the cloud.
What you can do with Llamatik
Chat privately on-device
Run AI conversations without sending data to external servers.
Generate content locally
Write, summarize, generate images, and explore ideas with full control.
Run models on mobile and desktop
Use AI directly on your device across platforms.
Try instantly in your browser
No installation required — start in seconds.
Build AI apps in Kotlin Multiplatform
Use the same platform powering the app.
Scale with local or remote inference
Run models on-device by default or use Llamatik Server when you need more power.
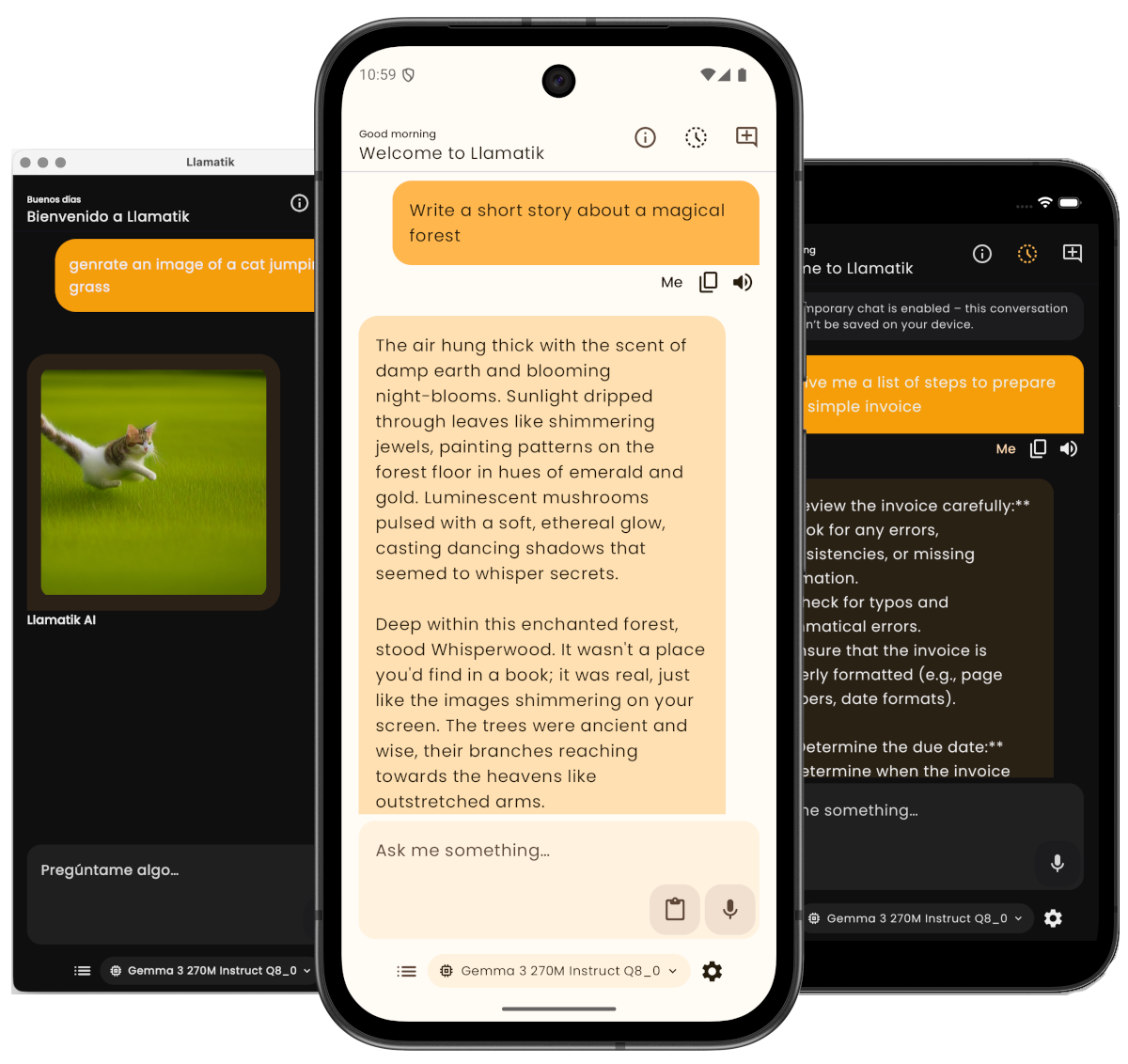
Use Llamatik or build with it
Llamatik App
Private AI, ready to use
Run AI directly on your device with no setup complexity.
- Chat with AI privately
- Generate content and ideas
- Run models locally
- No account required
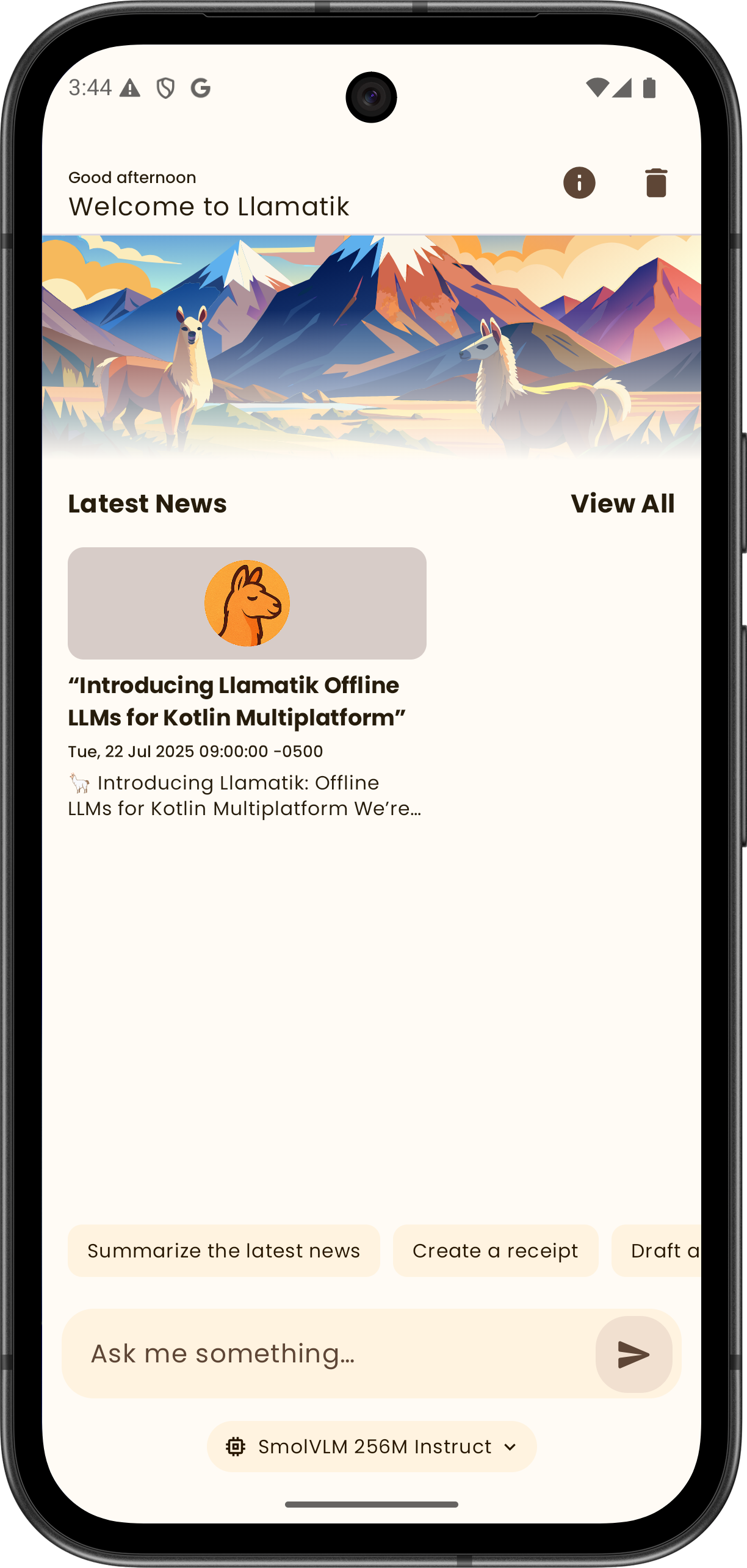
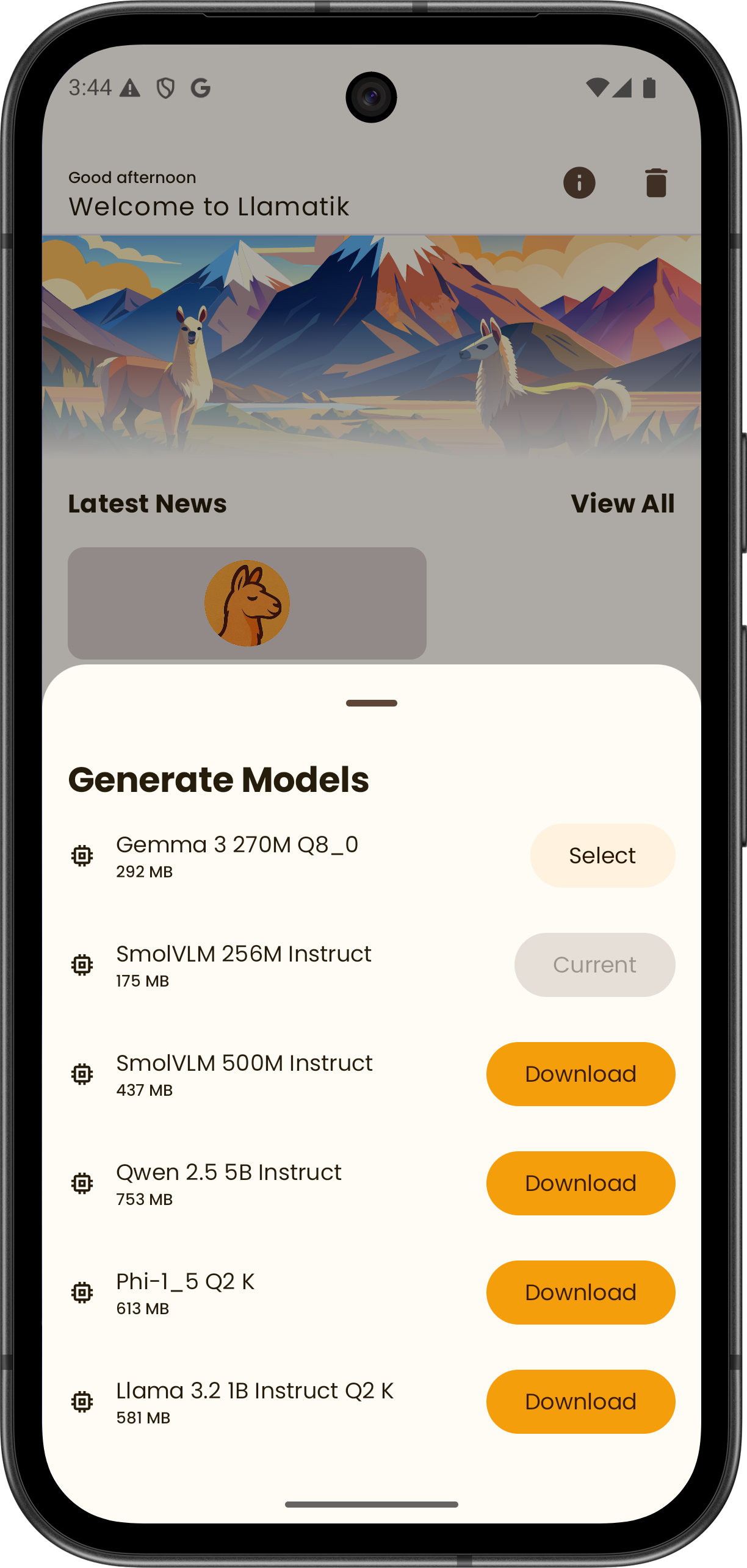

Llamatik Library
The platform behind the app
Build local-first AI into your own applications.
- On-device inference with llama.cpp, whisper.cpp and stable-diffusion.cpp
- Remote inference via Llamatik Server
- Unified API across Kotlin Multiplatform
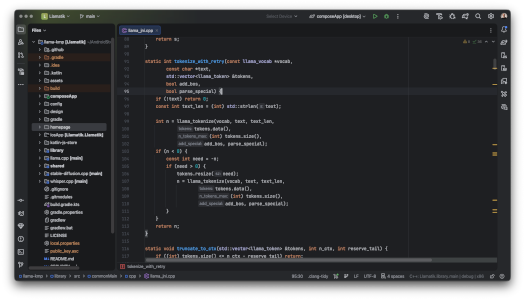
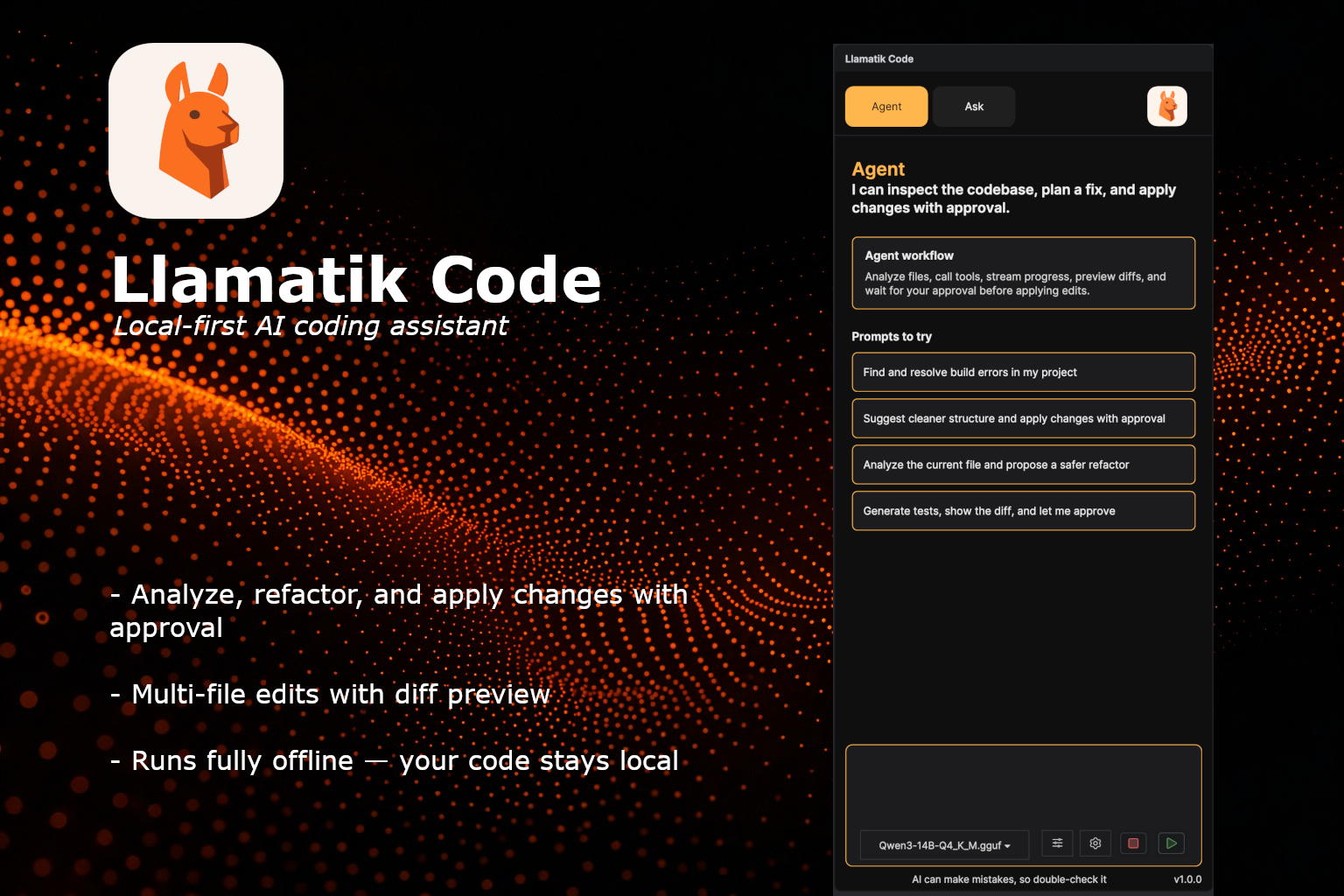
Llamatik Code
AI coding assistant, fully on-device
A privacy-first AI coding assistant for IntelliJ IDEA and Android Studio.
- Runs local LLM models directly inside your IDE
- Code completion, generation, and chat — no cloud required
- Powered by the same Llamatik engine
Built for privacy, control, and real-world use
Private by default
Your data stays on your device. No hidden tracking or external processing.
Local-first
Run AI on-device when possible, and use remote execution only when needed.
More efficient
Reduce latency, infrastructure costs, and complexity.
Why local-first AI matters
Cloud-based AI is powerful — but it comes with trade-offs: latency, recurring costs, privacy concerns, and vendor lock-in.
Llamatik runs models directly on user devices using native inference powered by llama.cpp, keeping sensitive data local and reducing infrastructure overhead.
When you need scale or centralized execution, you can use Llamatik Server — with the same API and architecture.
- Lower infrastructure costs
- Privacy by default
- Simpler architecture

For developers, the platform behind the app
Llamatik removes the complexity of integrating AI across platforms.
Instead of stitching together native bindings and platform-specific logic, you get a unified Kotlin-first abstraction that works across mobile, desktop, and backend environments.
On-device inference
Run LLMs fully offline using native llama.cpp bindings compiled for each platform. No network required, no data leakage.
Kotlin Multiplatform API
A single, shared Kotlin API for Android, iOS, desktop, and server — with expect/actual handled for you.
Remote inference
Use HTTP-based inference when models are too large or when centralized execution is required — without changing your app logic.
Text generation & embeddings
Built-in support for common LLM use cases like text generation, chat-style prompts, and vector embeddings.
GGUF model support
Works with modern GGUF-based models such as LLaMA, Mistral, and Phi.
Lightweight runtime
No heavy frameworks, no cloud SDKs. Just Kotlin, native binaries, and full control over your stack.
implementation("com.llamatik:library")
Built with trusted technology
Powered by battle-tested tools used in production apps.
![]()
![]()
![]() Compose Multiplatform
Compose Multiplatform
![]() Material Design 3
Material Design 3![]()
![]()
![]()
A growing local-first AI platform
Llamatik is evolving into a broader platform for building and using AI — all designed around privacy and local-first execution.
More tools coming
New integrations and tools will expand how you build and use local AI.
Open source and built in the open
Llamatik is open source and actively used by developers building local-first AI applications across mobile and desktop.
You can inspect the code, understand how it works, and use it in your own projects.
Start using private AI today
Download the app or try Llamatik instantly in your browser.

